Hash Tables
Suppose you work at a grocery store. When customer buys a product, you have to look up the price in a book. If the book is unalphbetized, it can take long time to look through every single line for banana. You'd be doing simple search, where you have to look at every line. As you already know simple search take O(n) time. If the book is alphabetized, you could run binary search to find the price of a banana. That would only take O(log n) time.
You already know that binary search is faster. But as a cashier, looking things up in a book is a pain, even if the book is sorted. What do you really need is something with all the names and prices memorized. Then you don't need to look up anything: you ask, and you will get the answer instantly.
The system can give you the price in O(1) time for any item, no matter how big the book is. It's even faster than binary search.
Awesome! How do you get that?
The answer is simple: hash functions.
Hash functions
A hash function is a function where you put in a string and you get back a number.
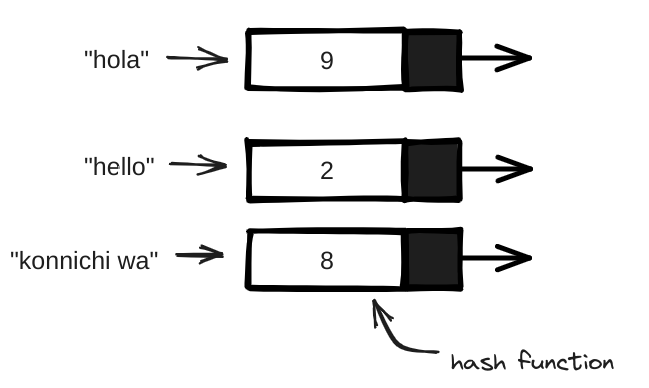
There are some requirements for hash functions:
- It need to be consistent.
- It should map different words to different numbers.
So a hash function maps strings to numbers. What is that good for? Well, you can use it to make your "price dictionary".
Start with an array
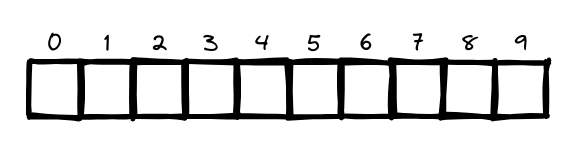
You'll store all your prices in the array, until the whole array is full.
And then you could ask for any price that you put it in.
The hash function tells you exactly where the price is stored, so you don't have to search at all! This works because:
- The hash function consistently maps a name to the same index.
- The hash function maps different strings to different indexes.
- The hash function knows how big your array is and only returns valid indexes.
Put a hash function and an array together, and you get a data structure called a hash table.
You'll probably never have to implement hash tables yourself.
Use cases
Hash tables are used everywhere.
Using hash tables for lookups
Your phone has a nice phone-book built in.
Each name has a phone number associated with it.
This is a perfect use case for hash tables! Hash tables are great when you want to:
- Create a mapping from one thing to another thing.
- Look something up.
How to create a phone-book?
- Make a new hash table:
>>> phone_book = {}
- Add the phone number of some people:
>>> phone_book["john"] = 1234
>>> phone_book["Kay"] = 4288
That's all! Now suppose you want to find the John's number. Just pass the key in the hash:
>>> print phone_book["john"]
1234 <------------- John's phone number
Hash tables are used for lookups on a much large scale. For example,
suppose you go to a website like https://google.com. Your computer
has to translate https://google.com to an IP address.
For any website you go to, the address has to be translated to an IP address.
https://google.com. ----> 64.233.160.0
A perfect use case for hash tables. This process is called DNS resolution. Hash tables are one way to provide this functionality.
Preventing duplicates entries
Suppose you have a huge library with thousands of books, and you want to organize them in a way that makes it easy to find any book quickly. However, you don't want to have duplicate copies of the same book taking up unnecessary space on the shelves.
Each book can be represented by its unique ISBN (International Standard Book Number), which acts as its identifier. The hash table will be like a virtual shelf where books are stored based on their ISBN.
Here's the code:
books = {}
def check_book(isbn):
if book.get(isbn):
print "already exists in the library"
else:
books[isbn] = True
print "add this book to the library"
Let's test it a few times:
>> check_book('1234')
add this book to the library
>> check_book('7878')
add this book to the library
>> check_book('7878')
already exists in the library
As you can see, when we tried to add the same book two times, it prints, "already exists in the library"
If you were storing these ISBN in a list, this function would eventually become really slow, because it would have to run a simple search over the entire list. But you're storing the ISBN in a hash table instead, and a hash table instantly tells you whether this book's ISBN is in the hash table or not. Checking for duplicates is very fast with a hash table.
Using hash tables as a cache
Suppose you visit twitter.com:
- You make a request to the Twitter's server.
- The server thinks for a second and comes up with the web page to send to you.
- You get a web page.
Caching is simple: websites remember the data instead of recalculating it.
If you're logged in to Twitter, all the content you see is tailored just for you. Each time you go to the twitter.com, it servers have to think about the content you're interested in. But if you're not logged in to Twitter, you see the login page. Everyone sees the same login page.Twitter is asked the same thing over and over: "Return to home page when the user is logged out". So it stops making the server do work to figure out what the home page looks like. Instead, it memorizes what the home page looks like and sends it to you.
This is called caching. It has two advantages:
- You get the website faster, just like when you memorized something.
- The server of the website has to do less work.
Caching is a common way to make things faster. All big websites use caching. And that data is cached in a hash!
Here it is in code:
cache = {}
def getPage(url):
if cache.get(url):
return cache(url) # returns cached data
else:
data = getDataFromServer(url)
cache[url] = data # saves this data is your cache first
return data
Here, you make the server do work only if the URL isn't in the cache. Before you return the data, though, you save it in the cache. The next time someone requests this URL, you can send the data from the cache instead of making the server do the work.
Recap
To recap, hashes are good for:
- Modeling relationships from one thing to another thing.
- Filtering out duplicates.
- Caching/memorizing date instead of making your server work.
Collisions
To understand the performance of hash tables, you first need to understand what collisions are.
A collision is when two keys have been assigned the same slot.
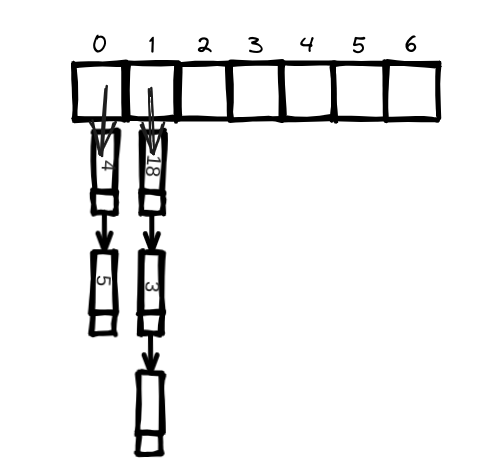
There are many different ways to deal with collisions. The simplest one is this: if multiple keys map to the same slot, start a linked list at that slot.
But suppose you have a hash table where you only store items that starts with the letter A.
The entire hash table is totally empty except for one slot. And that slot is a giant linked list! That's as bad putting everything in a linked list to begin with. It's going to slow down your the hash table.
There are two lessons here:
Your hash function is really important. Your hash function mapped all the keys to a single slot. Ideally, your hash function would map keys evenly all over the hash.
If those linked list get long, it slow down your hash table a lot. But they won't get long if you use a good hash function!
A good hash function will give you very few collisions.
Performance
In the average case, hash tables take O(1) for everything. O(1) is called constant time. It doesn't mean instant. It means the time taken will stay the same, regardless of how big the hash table is.
That means it doesn't matter whether your hash table has 1 element or 1 billion elements getting something out of a hash table will take the same amount of time.
In the worst case, a hash table takes O(n) or linear time for everything, which is really slow.
It's important that you don't hit worst-case performance with hash tables. And to do that, you need to avoid collisions. To avoid collisions you need
- A low load factor
- A good hash function
Note: Whatever programming language you use will have an implementation of hash tables built in. You can use the built-in hash table and assume it will have good performance.
Load factor
The load factor of a hash table is easy to calculate.
Number of items in hash tables divide by total number of slots.
Hash tables use an array for storage, so you count the number of occupied slots in an array.
Load factor measures how many empty slots remain in your hash table.
Having a load factor greater than 1 means you have more items than slots in your array.
Once the load factor start to grow, you need to add more slots to your hash table. This is called resizing.
The rule of thumb is to make an array that is twice the size. Then re-insert all those items into this new hash table using the hash function.
With a lower load factor, you'll have fewer collisions, and your table will perform better. A good rule of thumb is, resize when your load factor is greater than 0.7.
Hash tables take O(1) even with resizing.
A good hash functions
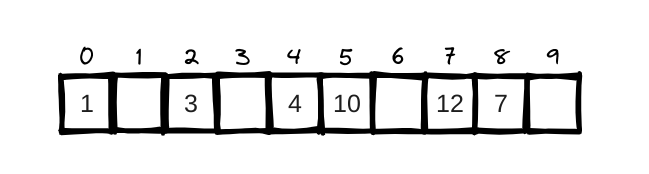
A good hash function distributes values in the array evenly.
A bad hash function groups values together and produces a lot of collisions.
Recap
- You'll never have to implement a hash function yourself.
- Hash tables have really fast search, insert and delete.
- Once your load factor is greater than 0.7, it's time to resize your hash table.
- Hash tables are used for modeling relationships from one item to another and caching data.
- Hash tables are great for catching duplicates.